ABSTRACT:
Single-response free association
has been the standard method for creating associates for a
target word, but it has shortcomings when the objective is
to create a broad set of associates. There are also some
pragmatic challenges such as the preponderance of
idiosyncratic responses and the lack of associate diversity
when a strong associate is present. A multiple-response
free association task with a new analytic approach is
introduced. This new approach is compared with the
traditional free association task in terms of response set
size and associate strengths. While data from the two tasks
are highly correlated, the new task generates broader
associate sets and raises the possibility that response
biases may influence single-response free association
measurements. The new method also provides a mechanism by
which individual differences could be studied.
A fundamental part of human behavior is the association of meaning
with an external stimulus. When we recognize a familiar face or
hear a mockingbird sing we are associating semantic information
stored in memory with an element of the real world. Within the
context of word recognition, this task is reduced to the
conversion of a symbolic stimulus (a word) into meaning without
many of the salient perceptual features present in a more
natural stimulus. By focusing on the semantic responses to a
word, we may be able to tap into high-level semantic processes
without substantial influence from the perceptual systems that
are likely to critically constrain the processing of natural
images.
Presumably, the
semantic information associated with a word is formed through
previous experiences with the stimulus, but it may also be
constrained by the neural representation of the information.
For instance, a representation based on the phonemic similarity
of two words would produce very different associates than a
representation based on the semantic similarity of two words.
Meyer and Schvaneveldt (1971) provided support for a
semantic-based representation of words when they showed that two
semantically related words were recognized quicker than two
semantically unrelated words. This finding initiated a wealth
of research on how semantic information can facilitate word
recognition (for a review, see McNamara, 2005).
One way to
assess the shared semantic representation of two words is by
using a Lexical Decision Task (LDT). In an LDT the recognition
of one word (e.g., “NURSE”) is faster when it is preceded by a
related word (e.g., “DOCTOR”) than when it is preceded by an
unrelated word (e.g., “VASE”). This approach, however, assumes
that there already exists a clear set of associated and
unassociated words. So, LDT can be used to evaluate the impact
of one word on the recognition of another word when the
relationship between the two words is already known.
Creating a list of
associated words has typically relied on a simple
single-response free association task (e. g. Nelson, McEvoy and
Dennis, 2000). Nelson, McEvoy and Schreiber (1998) have created
a database of free association data with over 5000 cue words and
the associative responses. This database has enabled
researchers to create a list of associates for many different
words based on the responses of approximately 100 participants
for each word. It is important to note, however, that there may
be several processes underlying word recognition and the extent
to which these processes overlap with the processes underlying
free association is an empirical question. For example, the
associates of a target word and the semantic neighbors of a
target word are likely to have words in common, but the two sets
of words will have some mutually exclusive words too. Perea &
Rosa (2002) have suggested that the influence of semantic
neighbors and associates may have different time profiles in the
LDT.
Single-response
free association (FA) norms have become a standard by which
other methods are compared. Maki (2007) compared ratings of
word relatedness to the associative strength measured by free
association tasks and concluded that ratings systematically
overestimate the associative strength of two words. Latent
Semantic Analysis (LSA) is a method for deriving word associates
based on the co-occurrence of words in text (Deerwester, Dumais,
Furnas, Landauer, and Harshman, 1990). Steyvers, Shiffrin and
Nelson (2004) compared associative networks derived from LSA
with those derived from FA norms. They concluded that LSA
captures a very broad semantic space while FA captures a narrow
semantic space. They also remarked that empirical methods for
capturing broad semantic spaces should be possible but are not
currently available.
The current
critique and assessment of FA is motivated by two objectives:
1) the desire to create a new method that captures a broader
semantic space than traditional FA, 2) the desire to capture a
more complete semantic representation of a word for a single
individual. The critique is focused on both methodological
challenges and theoretical challenges associated with FA.
Following the critique, a new method is proposed in hopes of
addressing some of the criticisms of FA and meeting the two
motivating objectives.
The FA task, by nature,
requires a distribution of responses gathered across several
individuals. The strength of an associated word is measured by
how many participants produced the word. Words that are
produced by many participants are assumed to have a stronger
association with the target word than words that are produced by
a few participants. Two extreme scenarios that can diminish
the value of the response distribution are when 1) each response
is generated by only a single participant and 2) all or most
participants produce the same common response. In the first
case, we are left with a large network of weak associates and
very little predictive value. In the second case, we are left
with a single strong associate with high predictive value which
may be fairly uninteresting.
Singletons and
idiosyncratic responses
In an FA task, when 100 participants are asked to respond to a
target word with a related word, it is common for some of the
participants to respond with a word that no other participant
generates. These words have been called idiosyncratic words or
singletons. Within the context of this discussion, a response
will be described as “idiosyncratic” if the response is
demonstrably unique to an individual (e.g., a proper name) while
a response will be described as a singleton if it is the product
of one individual. A singleton response may be idiosyncratic or
it may be a weak associate that could become a true associate
with a large participant count.
Singleton responses pose both a
practical and a theoretical challenge. Typically these
responses are all treated as idiosyncratic noise and discarded.
As a result, their presence diminishes the sample size and is
generally viewed as a problem. Theoretically, these responses
are problematic because we cannot objectively determine whether
the response is truly idiosyncratic to the individual or if the
word is simply a weak associate. For instance,
Nelson et al. (1998) report in the USF
norms that the word “HUSBAND” has prompted the responses
listed in Table 1, but with the exception of “STUPID”, the
singleton responses appear to be semantically linked to
“HUSBAND”. Although it is reasonable to remove truly
idiosyncratic responses from the associate list, declaring all
singletons to be noise appears to artificially narrow the scope
of associates.
Singleton responses can also be a
burden in terms of the magnitude of the responses which must be
discarded. In extreme cases, low frequency words such as
“USURP” have produced as many as 60% singleton responses (Nelson
et al., 1998). For the complete USF norm database (Nelson
et al., 1998), 17.7% of the responses for a target word
were singletons. As can be seen in Figure 1, only 15% of the
target words produced fewer than 10% singleton responses.
Table 1
Free
Association Responses for “HUSBAND” from Nelson, et al. (1998)
|
Response |
Frequency |
|
wife |
146 |
|
man |
3 |
|
spouse |
3 |
|
love |
2 |
|
father |
1 |
|
leader |
1 |
|
lover |
1 |
|
boyfriend |
1 |
|
males |
1 |
|
married |
1 |
|
mate |
1 |
|
stupid |
1 |
|
<No Response> |
3 |
Dominant Responses
Another type of response that can
overwhelm a free association task is the most common or
dominant response. For example, according to the USF norm
database, 96% of the responses to the cue “IN” were “OUT”. In
the whole USF database, dominant responses are much more common
across words than singletons with an average of 32% of responses
in the USF norm database being dominant responses. Although the
number of responses associated with the dominant word is clearly
important, this is an inefficiency in the single-response free
association task. As can be seen in Figure 2, the dominant
response was responsible for more than 10% of the responses for
all but 5% of the words.
The dominance of a single
response, whether appropriate or not, also reduces the
descriptive range of the associate list. With a small number of
participants offering alternatives to the dominant response, the
possibility that a relevant associate will be generated by two
of the participants is reduced. As a result, there is less
opportunity for non-singleton responses to gather association
strength. In short, a strong dominant associate shows strength
at the cost of other possible associates.
Words with strong
dominant responses tend to have a low proportion of singleton
responses and words with weak dominant responses tend to have a
high proportion of singleton responses (see Figure 3). In the
USF norms, the proportion of dominant responses and singleton
responses are negatively correlated (r = -.52; p < .0001; df =
5014).
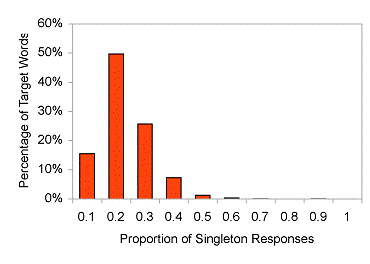
Fig 1.
The proportion of singleton responses for the words from the USF
norms (Nelson et al., 1998).
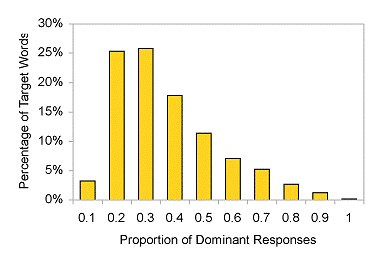
Fig 2.
The proportion of
dominant responses for the words from the USF norms (Nelson et
al., 1998).
This means that the distribution of responses for most words
will suffer from one of these two problems. In fact, half of
the responses in the USF norms are either singleton or dominant
responses with the lowest combined proportion of singletons and
dominant responses being the target “SOUP” with 20% of the
responses falling into either of these two categories. As
figure 4 indicates, the singleton and the dominant-response
inefficiencies are marginal challenges when viewed
independently, but since they are negatively correlated, they
combine into a broad substantial problem.
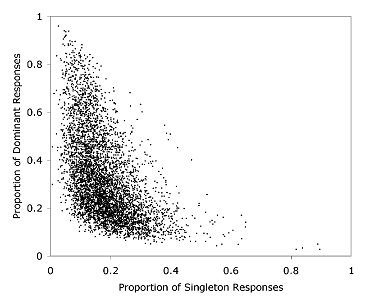
Fig 3.
A comparison of the dominant response count and the singleton
response count for the words from the USF norms (Nelson
et al., 1998).
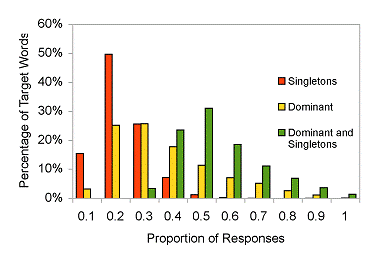
Fig 4.
The proportion of both
singleton dominant responses for each word from the USF norms
(Nelson et al., 1998).
Response Strategies
The cues “HUSBAND” and “IN” also
provide examples of the potential problem of response strategy
bias. While antonyms are clearly an important feature of the
semantic space, they may be overrepresented in a free
association task. It could be reasonably argued that the concept
of husband requires the existence of wife, but the
degree to which wife dominates (89% of all responses) the
other responses seems inappropriate. Participants may default
to a strategy of antonym production in order to reduce the pool
of associates. When a target word has an antonym this strategy
would simplify the task for the participant by narrowing the
selection of related words from which to choose. One result of
this strategy, however, would be an artificial amplification of
the antonym association strength at the cost of other
candidates.
Antonymy and synonmy have been
compared by Perea and Rosa (2002) with FA, LDT and a 9-point
semantic similarity scale. They did not find significant
differences between antonym pairs and synonym pairs with any
task. They did find a significant effect of the type of
semantic relationship when a third semantic relationship of
shared-category (e.g., cat-RABBIT) was included, but they
attributed this effect to word frequency and word length
differences between the categories. To our knowledge, a more
direct assessment of the antonym selection strategy in FA has
not been conducted, but it is an empirical question we are
investigating.
Collective
Response
Another limitation of using FA to develop semantic representations
is that it is inherently dependent on the responses of many
participants. Because the product of FA is a distribution of
responses across several participants, individual differences
and an understanding of the semantic space for a specific word
or a specific individual is unapproachable. The importance of
individual differences has recently been highlighted by Stolz,
Besner, and Carr (2005) in regard to the LDT. They found that
fundamental aspects of the data such as test-retest reliability
and inter-item reliability were present only at the group-level
of analysis and varied substantially from individual to
individual. Hutchison, Balota, Cortese and Watson (2007) have
suggested that a statistical normalization for reaction times
from an LDT may return reliability to the individual level, but
such a statistical correction is not likely for FA because the
response being measured is qualitative (a word) rather than
quantitative (a reaction time).
FA provides a
good measure of the set of associates averaged across
individuals and can be used to compare groups with different
hypothesized association networks. When looking at individual
differences, the best use for the FA data is to determine if an
individual is a member of one of two groups with hypothesized
different FA behaviors. Stacy (1997), for instance, has shown
that FA is an important part of a model used to distinguish
between individuals who will use alcohol or marijuana in the
future and individuals who will not use alcohol or marijuana in
the future. However, many questions about individual
differences are not approachable with the FA task. For example,
a hypothesis about the semantic network for a specific word for
a single individual would be very difficult, if not impossible,
to approach using the FA task.
New Methods
The points raised in the critique of FA broadly fall into three
categories: factors that artificially narrow the semantic span
for a target word, inefficiency in measuring association
strength, and a lack of sensitivity to individual differences.
I have developed a new method to overcome these challenges that
is aimed at creating a more complete semantic representation for
a single word in a single participant. In the method,
participants are asked to provide several associates for a
single target word.
McEvoy and Nelson
(1982) compared category norms gathered with one response and
category norms gathered with multiple responses and found set
sizes (the number of nonidiosyncratic responses for a target
category) were highly correlated. More recently, Nelson, et al.
(2000) compared free association responses with a single
response (FA-1) and two-responses (FA-2). Again, response set
size was correlated for the two tasks, but set size was
generally found to be larger when the second response was
included. The larger set size with FA-2 suggests, as Nelson, et
al. (2000) acknowledge, that FA-1 may underestimate the response
set size. They also suggest that the increase in set size was
largely the product of new words added as a second response and
they consider these associates to be less valid than
first-response associates, presumably because they may be less
directly linked to the original target word.
Nelson, et al. (2000)
concluded that pooling first and second responses in an FA-2
task decreased reliability in set size measurements as compared
to FA-1 set size. They also raised the concern that a chaining
response strategy in which response n may be an associate of
response n-1 rather than a true associate of the original target
word. Although their analysis discounted this concern about
chaining, the discrepancy between FA-2 pooled and FA-1 set sizes
led them to conclude that FA-1 tasks should be used.
Chaining falls into a
broader class of methodological concerns that have been raised
about within-subjects designs (Greenwald, 1976). When deciding
whether a study should be a within-subjects or a
between-subjects design, the statistical, methodological and
theoretical repercussions should be considered (for review, see
Keren, 1993). Perhaps the largest factor in determining which
design to use is the goal of the study. The goal of this study
is to develop a method that generates a more complete set of
word associates for a target word than is possible with the
traditional single-response free association task. Naturally,
the additional associates should be clearly related to the
target word and a model derived from the new task should be able
to better predict responses than a model derived from the
single-response task. This expectation led me to test the
predictive ability of the new method in the subsequent
analysis. If a model based on within-subjects data predicts
between-subjects data better than a model based on
between-subjects data, then concerns about comparing associates
across the designs should diminish.
To broaden the
semantic span for a target word, I used a five-response free
association task (FA-5). Using five responses increases the
opportunity for a chaining strategy to occur. To avoid the
potential influence of chaining, only words that were produced
as a first (of five) responses were considered associates, but
the strength of the association was based on the number of
individual who produced the associate word in any of the five
response positions. This approach allows a word that would have
been discarded as an idiosyncratic response to be treated as a
legitimate associate if it is supported by responses in
positions two through five.
METHOD
Participants
Sixty-four participants were given the FA-1 task and forty-seven
participants were given the FA-5 task. Five participants in the
FA-1 task and one participant in the FA-5 task reported that
their primary language was not English and, as a result, they
were excluded from the analysis. All participants were female
undergraduate students enrolled in psychology classes at Western
Kentucky University. Each participant earned credit for a class
research requirement and/or extra credit by participating in the
study. Participants were all female because the current study
was part of a screening process for a second project examining
behavioral changes across the menstrual cycle. The data
collection described in this study was approved by the Human
Subjects Review Board at Western Kentucky University.
Materials
Both the FA-1 and FA-5 tasks were conducted as paper-and-pencil
tasks. The FA-1 form had 120 words with 60 words on each page
in two columns. Beside each word was an underlined blank space
for the participant to write an associate word. The
instructions “Please write the first word that comes to your
mind when seeing the word provided.” were at the top of the page
in the FA-1 task. The FA-1 form used is in Appendix A. Twelve
participants used a version of this form that was missing
“DOCTOR” and “GOOD”. The FA-5 form had 20 words with 10 words
on each page and five numbered underlined spaces next to the
target word in two columns. The instructions at the top of each
page for the FA-5 task were “Please
write the first 5 words that come to your mind when seeing the
word provided.” The FA-5 form used is
in Appendix B. Nineteen of
the words in the FA-5 task were also present in the FA-5 task.
These nineteen common words will be the basis for the analysis
conducted.
Design and
Procedure
After answering a two-page demographics questionnaire, the
individuals participated in either the FA-1 or the FA-5 task. A
double-sided FA-1 page was used for all participants in the FA-1
condition and a double-sided FA-5 page was used for all
participants in the FA-5 condition. Half of the participants
in each group were given the page with one side first and the
other half of the participants in each group was given the page
with the other side first.
RESULTS
Set Sizes Across
Methods
Response set sizes were calculated for each word by counting only
the responses that were generated by two or more participants.
Set size calculations were made for FA-1 responses, all FA-5
responses, the first response of the FA-5 responses (FA-1/5),
and the first response of the FA-5 responses with frequencies
calculated from the whole FA-5 response set (extended FA-1/5).
The calculated set sizes for each of the 19 words present in
both tasks are in Table 2. The FA-1 and FA-1/5 set size
calculations were both made because the production of five
responses instead of a single response might have repercussions
on the first word produced.
The FA-1 (M
= 7.53, SD = 2.41) and FA-1/5 (M = 6.74, SD
= 1.85) set sizes were not significantly different with t(18)
= 1.62, p = .12 (paired, two-tailed). The extended
FA-1/5 (M = 14.11, SD = 3.68) set sizes were
significantly larger than the set sizes for FA-1/5 with t(18)
= 11.84, p < .001 (paired, one-tailed) but were still
significantly smaller than the FA-5 set sizes (M = 31.32,
SD = 4.12) with t(18) = 24.77, p < .001
(paired, one-tailed).
Association Strengths
The association strengths for FA-1/5 and extended FA-1/5 were
highly correlated. The correlations and t-values are shown in
Table 3. For all but one dominant response word, the
association strength was larger in the extended FA-1/5
calculation than in the FA-1/5 calculation. For six of the
nineteen words, however, a non-dominant associate received more
support than the original dominant associate. As a result, six
associates that had been the dominant associates in the FA-1/5
calculation were displaced by other associates when the extended
FA-1/5 calculation was used.
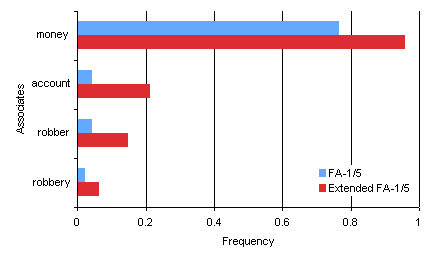
Fig 5.
The FA-1/5 response frequencies for the target “BANK” that had
the highest correlation between association strengths with and
without extension.
Figure 5 shows
the non-singleton associates for the target word (BANK, r = .98)
with the highest correlation between the FA-1/5 and extended
FA-1/5 association strengths. In this example, the extended
FA-1/5 calculation rendered the singleton “ROBBERY” a legitimate
associate and the associate “ACCOUNT” as a stronger associate
than “ROBBER” which had been its equal in the FA-1/5
calculation.
Figure 6 shows the
non-singleton associates for the target word (PARK, r = .60)
with the lowest correlation. The lowest nine associates were
singletons in the FA-1/5 calculation that were converted into
legitimate associates with support from second through fifth
responses. The most striking change is that “GRASS” which was a
singleton in the FA-1/5 calculation is the dominant response
with additional support. The support changed the ranking of
several associates but, as the correlation suggests, strong
associates generally received more support than weak associates.
Table 2
Set
Sizes Calculated from FA-1 and FA-5 Responses
|
|
FA-1 |
FA-5 |
FA-1/5 |
FA-1/5
Extended |
|
ARM |
5 |
38 |
7 |
18 |
|
BACK |
7 |
34 |
8 |
14 |
|
BANK |
3 |
25 |
3 |
4 |
|
CLAY |
11 |
30 |
9 |
17 |
|
CONTROL |
9 |
23 |
5 |
12 |
|
FORCE |
8 |
35 |
9 |
16 |
|
FRONT |
6 |
34 |
6 |
13 |
|
GAME |
9 |
32 |
8 |
15 |
|
HOME |
5 |
30 |
4 |
14 |
|
LABOR |
6 |
35 |
8 |
14 |
|
LEVEL |
7 |
35 |
7 |
20 |
|
MAD |
7 |
27 |
4 |
12 |
|
NEED |
6 |
30 |
6 |
13 |
|
NIGHT |
7 |
24 |
5 |
9 |
|
PARK |
12 |
34 |
9 |
18 |
|
ROCK |
11 |
32 |
6 |
13 |
|
SIDE |
11 |
34 |
8 |
13 |
|
WISE |
6 |
30 |
8 |
14 |
|
WOMEN |
7 |
33 |
8 |
19 |
|
Averages |
7.53 |
31.32 |
6.74 |
14.11 |
Table 3
Correlations
and T-tests for the FA-5 Target Words
|
|
Response Count |
Correlation Between FA1/5 and Extended
FA1/5 |
t |
|
ARM |
25 |
0.71 |
4.79 |
|
BACK |
25 |
0.77 |
5.83 |
|
BANK |
9 |
0.98 |
13.47 |
|
CLAY |
24 |
0.85 |
7.57 |
|
CONTROL |
33 |
0.68 |
5.16 |
|
FORCE |
29 |
0.79 |
6.71 |
|
FRONT |
20 |
0.86 |
7.32 |
|
GAME |
28 |
0.76 |
6.03 |
|
HOME |
31 |
0.73 |
5.74 |
|
LABOR |
21 |
0.95 |
13.45 |
|
LEVEL |
34 |
0.67 |
5.16 |
|
MAD |
19 |
0.86 |
6.99 |
|
NEED |
19 |
0.82 |
5.9 |
|
NIGHT |
17 |
0.70 |
3.76 |
|
PARK |
26 |
0.60 |
3.65 |
|
ROCK |
21 |
0.83 |
6.5 |
|
SIDE |
29 |
0.72 |
5.42 |
|
WISE |
19 |
0.93 |
10.36 |
|
WOMEN |
26 |
0.81 |
6.85 |
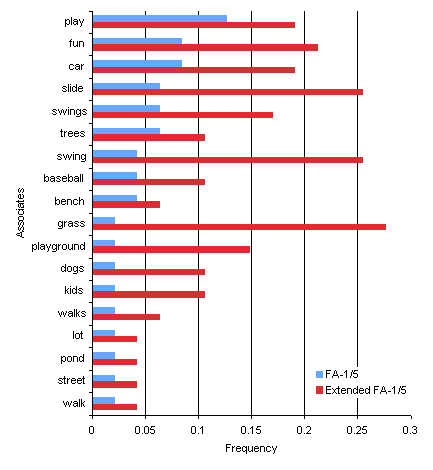
Fig 6.
The FA-1/5 response frequencies for the target “PARK” that had
the lowest correlation between association strengths with and
without extension.
Ability to Predict
Associates
If the extension of the task to include five responses to support
the initial response creates a more accurate representation of
the semantic connections between words, then a model based on
the new extended task should predict associate generation better
than a model based only on the first response. To test this
hypothesized increase in predictive ability, simple models of
association were created and tested using ten-fold
cross-validation.
For each target
word, one-tenth of the FA-5 dataset was set aside for testing
and a frequency distribution was created based only on the first
response in the remaining nine-tenths of the dataset. Each
word that occurred two or more times in the training set was
included in the associate list. The predictive ability of the
associate list was tested by counting the number of
first-responses in the test set that were predicted by the
associate list from the training set. This process was repeated
ten times with a different tenth of the dataset used as the
testing set and an average number of predicted responses was
created for each target word. Since there were 46 participants,
the training set size alternated between 41 and 42 while the
testing set size alternating between 5 and 4.
Associate lists
based on the extended FA-1/5 data were similarly created and
tested with ten-fold cross-validation. The average number of
predicted responses in the test set for all target words is
plotted in Figure 7. For seventeen of the nineteen target
words, the extended FA-1/5 models (M = 2.37, SD =
.50) predicted more test words than the FA-1/5 models (M
= 1.83, SD = .39) with t(18)=8.97, p <.001
(paired, one-tailed).
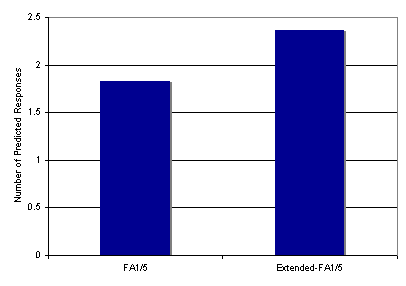
Fig 7.
The predictive ability of FA-1/5 and extended FA-1/5 assessed
using ten-fold cross-validation.
DISCUSSION
The single-response free association task is excellent for
acquiring a list of the strong associates for many words, but it
has shortcomings when the focus is on a complete set of
associates or on individual differences. Requiring multiple
responses to each target word raises the possible problem of a
chaining response strategy in which a response is influenced by
the preceding response rather than the original target word.
One way to ensure that associates are not the product of
chaining, but due to a direct association with the target word
is to require that each associate occur at least once as a first
response in the dataset. Once this criterion has been met,
association strength can be calculated based on the number of
individuals who gave the associate as a response in any of the
response positions. This additional support allows singletons
that are not idiosyncratic to be included in the associate list
for a target word. The support from multiple responses also
reduces competition between associates. While dominant
associates remain strong in this extended FA-1/5 approach, the
cost of a dominant response on the diversity of associates is
reduced. After choosing a dominant associate, a participant
still has opportunities to provide other associates.
Although it
would be premature to draw conclusions about the impact of
multiple responses on response strategies like the antonym
response strategy, the results for FRONT suggest that this is an
issue worth considering. As is shown in Figure 8, the dominant
associate for FRONT was “BACK” in both the FA-1/5 and the
extended FA-1/5 calculations, but the non-dominant responses
“FACE” and “DOOR” both receive more additional support than
“BACK”. This could be a simple shift of associates, but it is
also consistent with first-responses being biased towards
antonyms in a way that multiple-responses are not.
In terms of gathering
information on the largest number of target words, acquiring
support from additional responses is clearly inefficient because
it takes much more time for a participant to create five
associates for a word than one associate. If, on the other
hand, the objective is to create a complete description of a
target word, then this extended FA method is more efficient.
Table 4 shows the average percentage of singleton and dominant
responses for the FA-1/5 responses and the extended FA-1/5
responses. The percentage of responses that do not fall into
either of these two categories is also provided. It is this
last category that should be maximized in order to create a
complete description of the target word because it represents
the responses that are strengthening non-dominant associates.
In summary, the
extended free association task provides a diverse set of
associates for a single word in a way that rules out chaining
and makes it possible for individual differences to be
considered. The task is not a general replacement for
traditional FA, but may be used to assess hypotheses with
specific predictions about the links between a word and a fairly
broad semantic context. Discrepancies between traditional FA
and extended FA may also reveal word production strategies that
may or may not reflect differences in the underlying semantic
representation. Finally, because there are several responses
gathered from each individual for each target word, the task may
also be more sensitive to individual differences than
traditional FA.
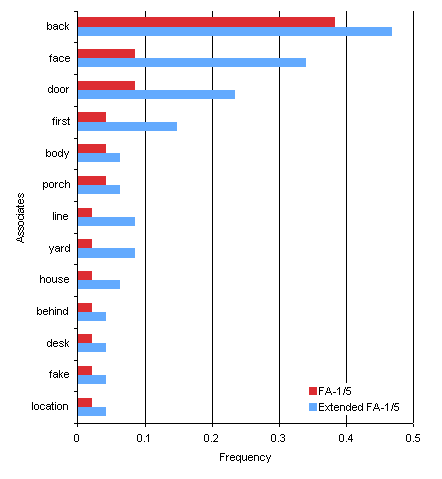
Fig 8. The FA-1/5 response frequencies for the
target "FRONT" that had secondary responses
acquire more support than the
dominant antonym when extension was used.
Table 4
Dominant,
Singleton and Other Responses for FA-5 Task with and without
Extension
|
|
FA-1/5 |
Extended
FA-1/5 |
|
Dominant
Responses |
25.5% |
21.5% |
|
Singleton
Responses |
37.8% |
9.9% |
|
Non-dominant,
Non-singleton Responses |
36.7% |
68.6% |
Note. FA-1/5 percentages were
calculated based on the total number of participants providing a
first response. Extended FA-1/5 percentages were calculated
based on the total number of responses (five per participant)
excluding the responses that never appeared as the first
response.
Implications of
extended FA-1/5 for understanding semantic memory
The main motivation for creating extended FA-1/5 was to enable the
creation of a detailed list of associates for a target word with
an increased focus on the representation provided by a single
participant. A high-resolution associative map for a word has
the potential to impact the study of semantic memory in at least
two important ways. First, there is currently a disconnect
between free association and other measures of word
associativity (e.g. word relatedness and Latent Semantic
Analysis). One potential cause for this disconnect is that
traditional free association measures the relatedness between
words that are strongly related while LSA and word relatedness
tasks capture very broad semantic spaces. By broadening the
semantic space captured, extended FA-1/5 has the potential to
reveal a theory of semantic memory that unifies FA, LSA and word
relatedness.
Second, there
is a growing interest in the gross network properties of
semantic memory (i.e. Steyvers and Tenenbaum, 2005) that is
often based on single-response free association. Limiting these
network models of semantic memory to only the strong responses
may lead to conclusions that simplify the theorized network and
reduce connectivity. The level of connectivity is fundamentally
important to these models. If connectivity is underestimated,
then the fundamental computation used to describe the flow of
activation would be based on false assumptions (Nelson, McEvoy
and Pointer, 2003).
The increased
focus on the semantic map for a single individual has the
potential to add a third important impact on the study of
semantic memory in the area of group and individual differences.
While group differences have been measured across words (e.g.
Stacy, 1997), this new task allows a closer inspection of the
semantic representations.
For instance, it
would be reasonable to expect gender differences in the
associative networks for some words. LABOR may evoke associates
such as BIRTH and HOSPITAL for women while evoking associates
such as WORK and MANUAL for men. By acquiring several
associates for an individual, we can determine if individuals
cling to a single salient definition (LABOR: BIRTH, HOSPITAL)
or are flexible (LABOR: BIRTH, WORK).
Finally,
requiring a participant to generate several associates may be
useful in assessing aspects of the individual. An inability to
produce more than the obvious associates may indicate a
restricted vocabulary or a reduced reading ability. Producing
negative associates within a specific semantic domain may reveal
negative emotions associated with that domain. In summary, when
the empirical focus is on individual differences or the detailed
semantic representation of a word, extended FA-1/5 overcomes
many of the drawbacks of single-response FA and provides new
clarity in the investigation of semantic memory.
REFERENCES
Deerwester, S., Dumais,
S. T., Furnas, G. W., Landauer, T. K., & Harshman, R. (1990).
Indexing by latent semantic analysis. Journal of the
American Society For Information Science, 41,
391-407.
Greenwald, A. G.
(1976). Within-subjects designs: To use or not to use?
Psychological Bulletin, 83, 314-320.
Hutchison, K. A.,
Balota, D. A., Cortese, M. J., Watson, J. M. (2007). Predicting
semantic priming at the item level. The Quarterly Journal of
Experimental Psychology, 1, 1-31. Retrieved May 21,
2008, from
http://www.informaworld.com/smpp/content~db=all?content=10.1080/17470210701438111
Keren, G. (1993)
Between- or within-subjects design: A methodological dilemma.
In G. Keren & C. Lewis (Eds.), A Handbook for Data Analysis
in Behavioral Sciences (pp. 257-272). Hillsdale, NJ: L.
Erlbaum Associates.
Maki, W. S. (2007).
Judgments of associative memory. Cognitive Psychology,
54, 319-353.
McEvoy, C. L., &
Nelson, D. L. (1982). Category name and instance norms for 106
categories of various
sizes. American Journal of Psychology, 95, 581-634.
McNamara, T. P.
(2005). Semantic priming: Perspectives from memory and word.
New York: Taylor & Francis Group.
Meyer, D. E. &
Schvaneveldt, R. W. (1971) Facilitation in recognizing pairs of
words: evidence of a dependence between retrieval operations.
Journal of Experimental Psychology, 90, 227-234.
Nelson, D., McEvoy,
C., & Dennis, S. (2000). What is and what does free association
measure? Memory & Cognition, 28, 887-899.
Nelson, D., McEvoy,
C., & Pointer, L. (2003). Spreading activation or spooky action
at a distance? Journal of Experimental Psychology: Learning,
Memory and Cognition, 29, 42-52.
Nelson, D. L., McEvoy,
C. L., & Schreiber, T. A. (1998). The University of South
Florida word association, rhyme, and word fragment norms.
Retrieved May 18, 2007, from http://www.usf.edu/FreeAssociation/
Perea, M., & Rosa, E.
(2002). The effects of associative and semantic priming in the
lexical decision task. Psychological Research, 66,
180-194.
Stacy, A. W. (1997).
Memory activation and expectancy as prospective predictors of
alcohol and marijuana use. Journal of Abnormal Psychology,
106, 61-73.
Steyvers, M. Shiffrin,
R. M. & Nelson, D. L. (2004). Word association spaces for
predicting semantic similarity effects in episodic memory. In
A. F. Healy (Ed.), Experimental Cognitive Psychology and its
Applications. Festschrift in honor of Lyle Bourne, Walter
Kintsch, and Thomas Landauer (pp. 237-240). Washington,
DC: American Psychological Association.
Stolz, J. A., Besner,
D., & Carr, T. H. (2005). Implications of measure of
reliability for theories of priming: Activity in semantic
memory is inherently noisy and uncoordinated. Visual
Cognition, 12, 284-336.
APPENDIX A: FA-1 FORM


